AVI 是一种比较老的视频格式,现代浏览器通常不直接支持 AVI 格式,因此在网页上播放 AVI 视频时,您需要将视频转换为一种更常见的格式(如 MP4),或使用一些第三方的 JavaScript 播放器库。
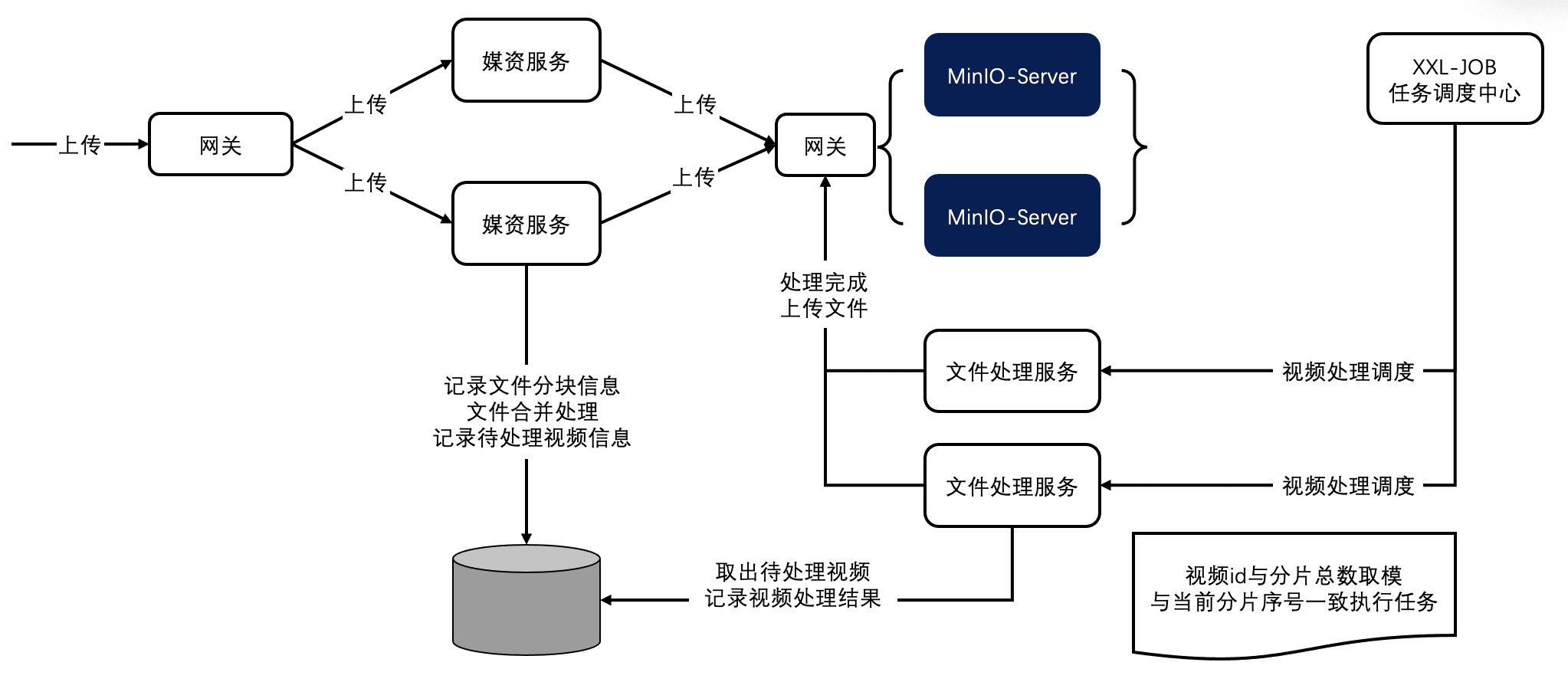
下面是整个转码服务的运行过程
FFmpeg处理视频 使用FFmpeg 进行视频转码操作
分布式任务调度 XXL-JOB 是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
如何保证任务不重复执行?
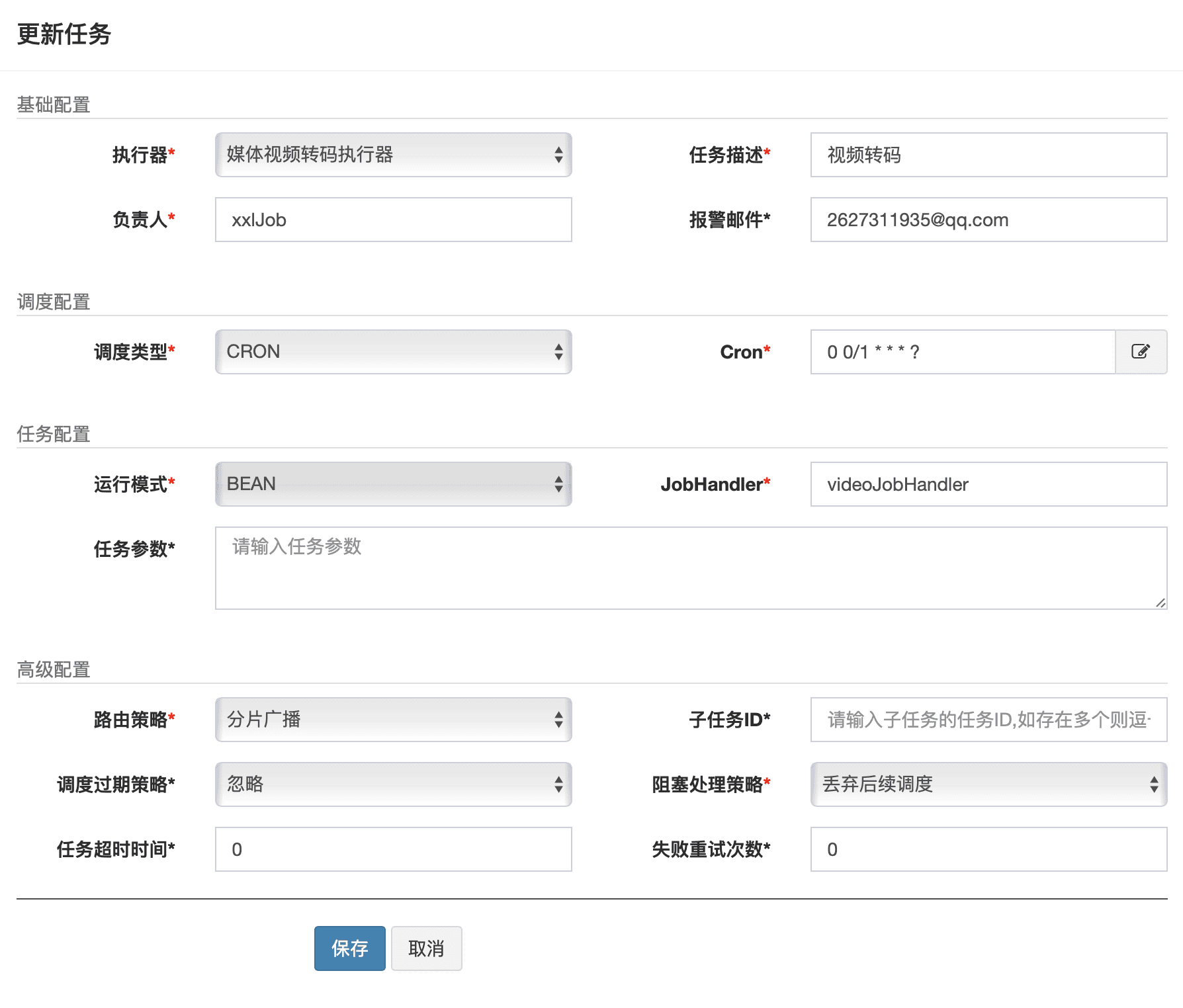
1)调度中心按分片广播的方式去下发任务
任务幂等性如何保证?
它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果。
幂等性是为了解決重复提交问题,比如:恶意刷单,重复支付等。
解决幂等性常用的方案:
1)数据库约束,比如:唯一素引,主键。同一个主键不可能两次都插入成功。
这里我们在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断
安装XXL-JOB 使用Docker部署,使用下面命令安装:
docker pull xuxueli/xxl-job-admin:2.3.0
使用如下命令启动:
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://ip:3306/xxl_job?useSSL=false&serverTimezone=UTC&characterEncoding=utf-8&allowPublicKeyRetrieval=true \ --spring.datasource.driverClassName=com.mysql.cj.jdbc.Driver \ --spring.datasource.username=root \ --spring.datasource.password=root" \
注意修改数据源,其中url中的IP设置为服务器IP地址,如果是本机,请使用本机地址不要使用localhost或者127.0.0.1,同时记得开启mysql的远程访问
use mysql;
访问http://localhost:8080/xxl-job-admin/
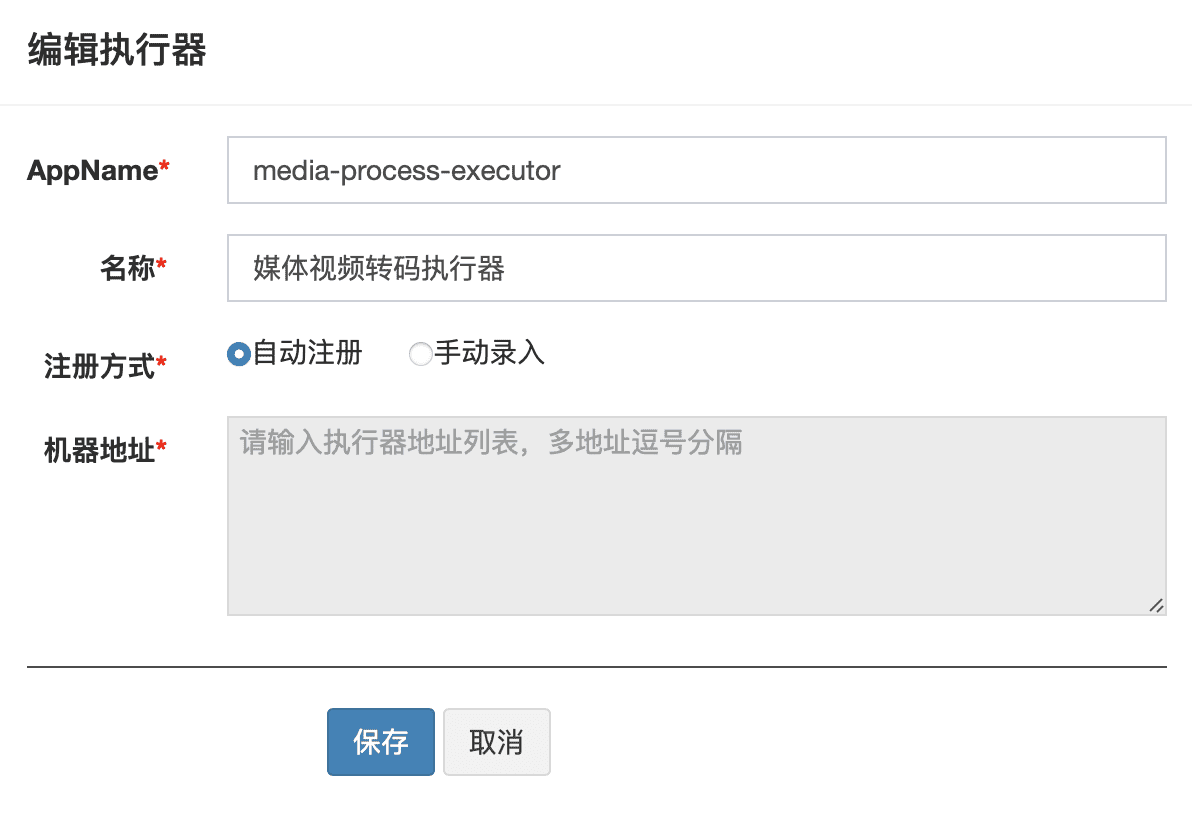
创建执行器 进入后台管理,点击右侧执行器管理 ,新建一个执行器
注册执行器 进入Nacos后台,找到media-service-dev.yaml,添加xxl-Job的配置:
media-service-dev.yaml xxl: job: admin: addresses: http://127.0.0.1:8080/xxl-job-admin executor: address: appname: media-process-executor ip: port: 9999 logpath: /Users/swcode/data/applogs/xxl-job/jobhandler logretentiondays: 30 accessToken:
找到learning-online-media-service模块,在config包下创建XxlJonConfig配置类
XxlJonConfig @Slf4j @Configuration public class XxlJonConfig {@Value("${xxl.job.admin.addresses}") private String adminAddresses;@Value("${xxl.job.executor.appname}") private String appname;@Value("${xxl.job.executor.address}") private String address;@Value("${xxl.job.executor.ip}") private String ip;@Value("${xxl.job.executor.port}") private int port;@Value("${xxl.job.accessToken}") private String accessToken;@Value("${xxl.job.executor.logpath}") private String logPath;@Value("${xxl.job.executor.logretentiondays}") private int logRetentionDays;@Bean public XxlJobSpringExecutor xxlJobExecutor () {">>>>>>>>>>> xxl-job config init." );XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor ();return xxlJobSpringExecutor;
启动learning-online-media服务,在执行器管理 页面可以看到自动注册了一个服务。
添加任务管理 进入后台管理,点击右侧任务管理 ,新建一个任务
分布式锁 买现分布式锁的方案有很多,常用的如下:
2、基于redis实现锁
3、使用zookeeper实现
本次我们使用数据库实现分布锁,后边的模块会使用其它方法到时再洋细介绍,
使用乐观锁机制实现
当某次调用者执行成功时,status被置为4,其他执行都会失败;这个执行成功的就拿到了”锁”。
MediaProcessMapper public interface MediaProcessMapper extends BaseMapper <MediaProcess> {@Update("update media_process set status = '4' where (status='1' or status='3') and fail_count<3 and id=#{id}") int startTask (@Param("id") Long id) ;
Service包一层
MediaProcessService public interface MediaProcessService extends IService <MediaProcess> {public boolean startTask (long id) ;
实现该方法
MediaProcessServiceImpl @Service public class MediaProcessServiceImpl extends ServiceImpl <MediaProcessMapper, MediaProcess> implements MediaProcessService {@Override public boolean startTask (long id) {return baseMapper.startTask(id) > 0 ;
实现添加任务 在文件合并完成之后,将数据保存到media_files同时,判断视频文件是否为.avi,如果是需要进行转码操作,将其添加到任务表media_process。
找到MediaFilesServiceImpl,修改saveAfterStore方法
MediaFilesServiceImpl @Override public MediaFiles saveAfterStore (UploadFileParamDTO dto, Long companyId, String fileMd5, String bucket, String path) {MediaFiles mediaFiles = new MediaFiles ();"/" + bucket + "/" + path);"002003" );boolean save = save(mediaFiles);if (!save) {"想数据库保存文件失败,bucket: {},文件名: {}" , bucket, path);return null ;return mediaFiles;private void addWaitingTask (MediaFiles mediaFiles) {String filename = mediaFiles.getFilename();String suffix = filename.substring(filename.lastIndexOf("." ));String mineType = getMineType(suffix);if (!mineType.equals("video/x-msvideo" )) {return ;MediaProcess mediaProcess = new MediaProcess ();"1" );0 );null );
更新任务状态 任务处理完成需要更新任务处理结果,任务执行成功更新视频的URL、及任务处理结果,将待处理任务记录删除,同时向历史任务表添加记录。
创建MediaProcessSaveService接口添加方法
MediaProcessSaveService.java public interface MediaProcessSaveService {public void saveProcessFinishStatus (Long taskId, String status, String fileId, String url, String errorMsg) ;
创建实现类MediaProcessSaveServiceImpl实现保存方法:
MediaProcessSaveServiceImpl @Service public class MediaProcessSaveServiceImpl implements MediaProcessSaveService {private final MediaFilesService mediaFilesService;private final MediaProcessService mediaProcessService;private final MediaProcessHistoryService mediaProcessHistoryService;public MediaProcessSaveServiceImpl (MediaFilesService mediaFilesService, MediaProcessService mediaProcessService, MediaProcessHistoryService mediaProcessHistoryService) {this .mediaFilesService = mediaFilesService;this .mediaProcessService = mediaProcessService;this .mediaProcessHistoryService = mediaProcessHistoryService;@Override @Transactional(rollbackFor = Exception.class) public void saveProcessFinishStatus (Long taskId, String status, String fileId, String url, String errorMsg) {MediaProcess dbProcess = mediaProcessService.getById(taskId);if (dbProcess == null ) {return ;if (status.equals(ProcessStatus.PROCESS_FAIL.status())) {1 )return ;MediaFiles mediaFiles = mediaFilesService.getById(fileId);if (mediaFiles == null ) {return ;MediaProcessHistory processHistory = new MediaProcessHistory ();
实现获取任务 从数据库中获取任务,根据分片数量和当前分片序号确定当前分片要处理的任务。
找到MediaProcessMapper,添加查询任务方法:
MediaProcessMapper @Select("select * from media_process t where t.id % #{shardTotal} = #{shardIndex} and t.status <> 2 and t.fail_count < 3 limit #{count}") selectListByShardIndex (@Param("shardTotal") int shardTotal, @Param("shardIndex") int shardIndex, @Param("count") int count) ;
包一层MediaProcessService
MediaProcessService getMediaProcessList (int shardTotal, int shardIndex, int count) ;
实现该方法,MediaProcessServiceImpl
MediaProcessServiceImpl @Override public List<MediaProcess> getMediaProcessList (int shardTotal, int shardIndex, int count) {return baseMapper.selectListByShardIndex(shardTotal, shardIndex, count);
实现调度任务 创建包com.swx.media.service.jobhandle,并创建视频编码任务VideoTask
根据系统CPU核心数,确定从数据库查询多少任务,如果任务为0则直接返回;
根据获取的任务数,开启对应数量的线程数;
使用计数器,确保所有任务执行完成后再结束方法;
循环所有任务,指定线程取执行如下步骤:
获取任务锁,实现幂等性,防止重复执行,失败,写入数据库,返回;
从MinIO下载要转码的视频,下载失败,写入数据库,返回;
使用FFmpeg进行视频转码,保存到临时文件;转码失败,写入数据库,返回;
将转码之后的文件上传到MinIO中,上传失败,写入数据库,返回;
上传成功,写入数据库。
使用try finally包裹线程方法,在finally中将计数器减1;
使用计数器阻塞进程,并设置最大等待时间,无论线程中计数器是否减1,最大时间过后释放线程。
VideoTask @Slf4j @Component public class VideoTask {private final MediaProcessService mediaProcessService;private final FileStorageService fileStorageService;private final MediaProcessSaveService mediaProcessSaveService;public VideoTask (MediaProcessService mediaProcessService, FileStorageService fileStorageService, MediaProcessSaveService mediaProcessSaveService) {this .mediaProcessService = mediaProcessService;this .fileStorageService = fileStorageService;this .mediaProcessSaveService = mediaProcessSaveService;@XxlJob("videoJobHandler") public void videoJobHandler () throws Exception {int shardIndex = XxlJobHelper.getShardIndex();int shardTotal = XxlJobHelper.getShardTotal();int processors = Runtime.getRuntime().availableProcessors();int size = mediaProcessList.size();if (size == 0 ) {"取到的视频处理任务数:{}" , size);return ;ExecutorService executorService = Executors.newFixedThreadPool(size);CountDownLatch countDownLatch = new CountDownLatch (size);for (MediaProcess mediaProcess : mediaProcessList) {try {Long taskId = mediaProcess.getId();boolean lock = mediaProcessService.startTask(taskId);String fileId = mediaProcess.getFileId();if (!lock) {"抢占任务失败,任务id: {}" , taskId);return ;String bucket = mediaProcess.getBucket();String objectName = mediaProcess.getFilePath();File file = fileStorageService.downloadFile(bucket, objectName);if (file == null ) {"下载视频出错,任务id: {}, bucket: {}, objectName: {}" , taskId, bucket, objectName);null , "下载视频到本地失败" );return ;File sourcePath = file.getAbsoluteFile();File targetFile = null ;try {"minio" , ".mp4" );catch (IOException e) {"创建临时文件异常, " , e);null , "创建临时文件异常" );return ;String targetPath = targetFile.getAbsolutePath();String result = "success" ;if (!result.equals("success" )) {"视频转码失败, bucket: {}, objectName: {}, 原因: {}" , taskId, bucket, result);null , result);return ;FileInputStream fileInputStream = null ;try {new FileInputStream (targetPath);catch (FileNotFoundException e) {"转码后的文件不存在, 文件路径: {}" , targetPath);null , "转码后的文件不存在" );return ;boolean isUploadMinIO = fileStorageService.uploadVideoFile(objectName, "video/mp4" , fileInputStream);if (!isUploadMinIO) {"上传mp4到MinIO失败, taskId: {}" , taskId);null , "上传mp4到MinIO失败" );return ;String url = getFilePathByMd5(fileId, ".mp4" );null );finally {30 , TimeUnit.MINUTES);private String getFilePathByMd5 (String fileMd5, String suffix) {return fileMd5.charAt(0 ) + "/" + fileMd5.charAt(1 ) + "/" + fileMd5 + "/" + fileMd5 + suffix;