单点Redis的问题
数据丢失问题:Redis是内存存储,服务器重启可能丢失数据
- 实现Redis数据持久化
并发能力问题:单节点Redis并发能力虽然不错,但也无法满足如618这样的高并发场景
- 搭建主从集群,实现读写分离
故障恢复问题:如果Redis宕机,则服务不可用,需要一种自动恢复手段
- 利用Redis哨兵,实现健康检测和自动恢复
存储能力问题:Redis基于内存,单节点存储的数据量难以满足海量数据需求
- 搭建分片集群,利用插槽机制实现动态扩容
Redis持久化
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也叫Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件成为RDB,默认保存在当前运行目录
- save:由Redis主进程来执行RDB,会阻塞所有命令
- bgsave:开启子进程执行RDB,避免主进程收到影响
Reids停机会执行一次RDB
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下
|
RDB的其他配置也可以在redis.conf文件中设置:
|
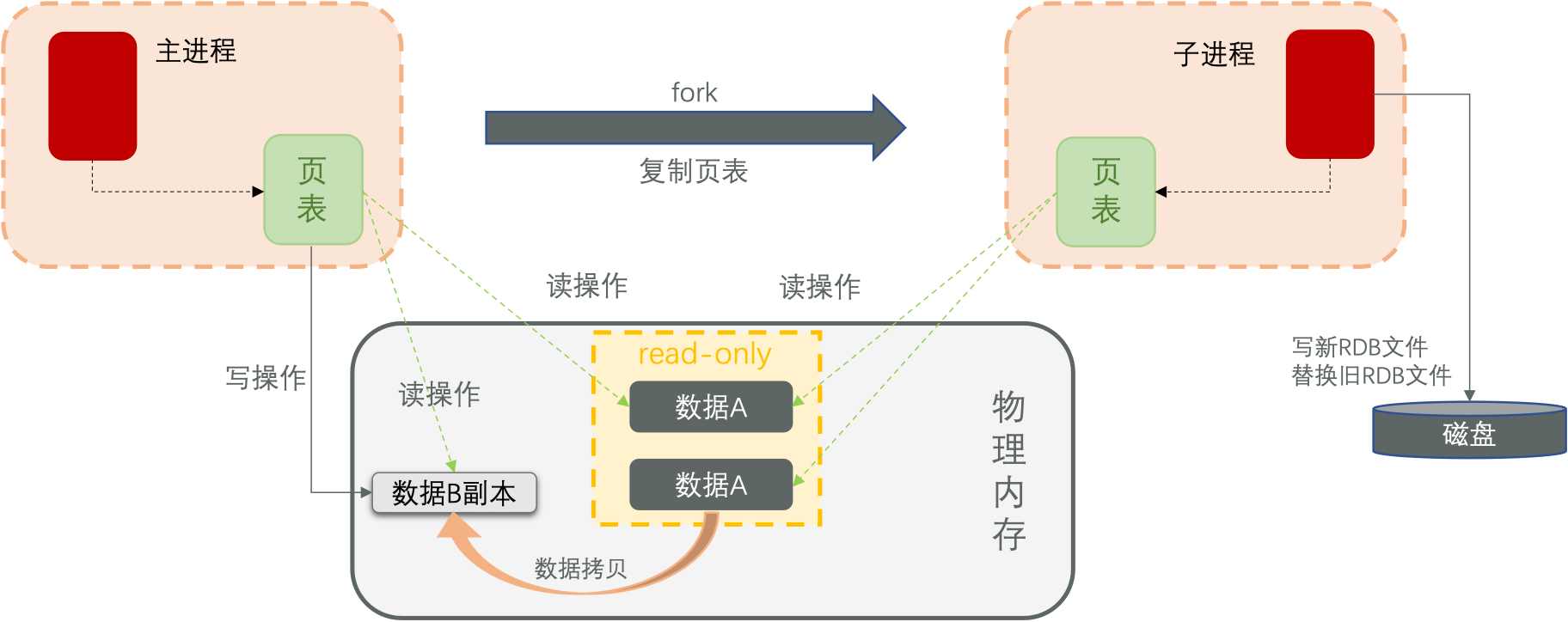
bgsave开始会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
总结
RDB方式bgsave的基本流程
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认时服务停止时。
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行时隔时间长,两次RDB之间写数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。恢复时,从头执行文件中的命令。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
|
AOF的命令记录的频率也可以通过redis.conf文件来配:
|
no: don’t fsync, just let the OS flush the data when it wants. Faster.
always: fsync after every write to the append only log. Slow, Safest.
everysec: fsync only one time every second. Compromise.
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1s数据 |
| no | 操作系统控制 | 性能最好 | 可靠性差,肯能丢失大量数据 |
重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
|
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置
|
比较
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存 |
| 使用场景 | 可以容忍数分钟的数据丢失 追求更快的启动速度 |
对数据安全性要求较高常见 |
Redis主从
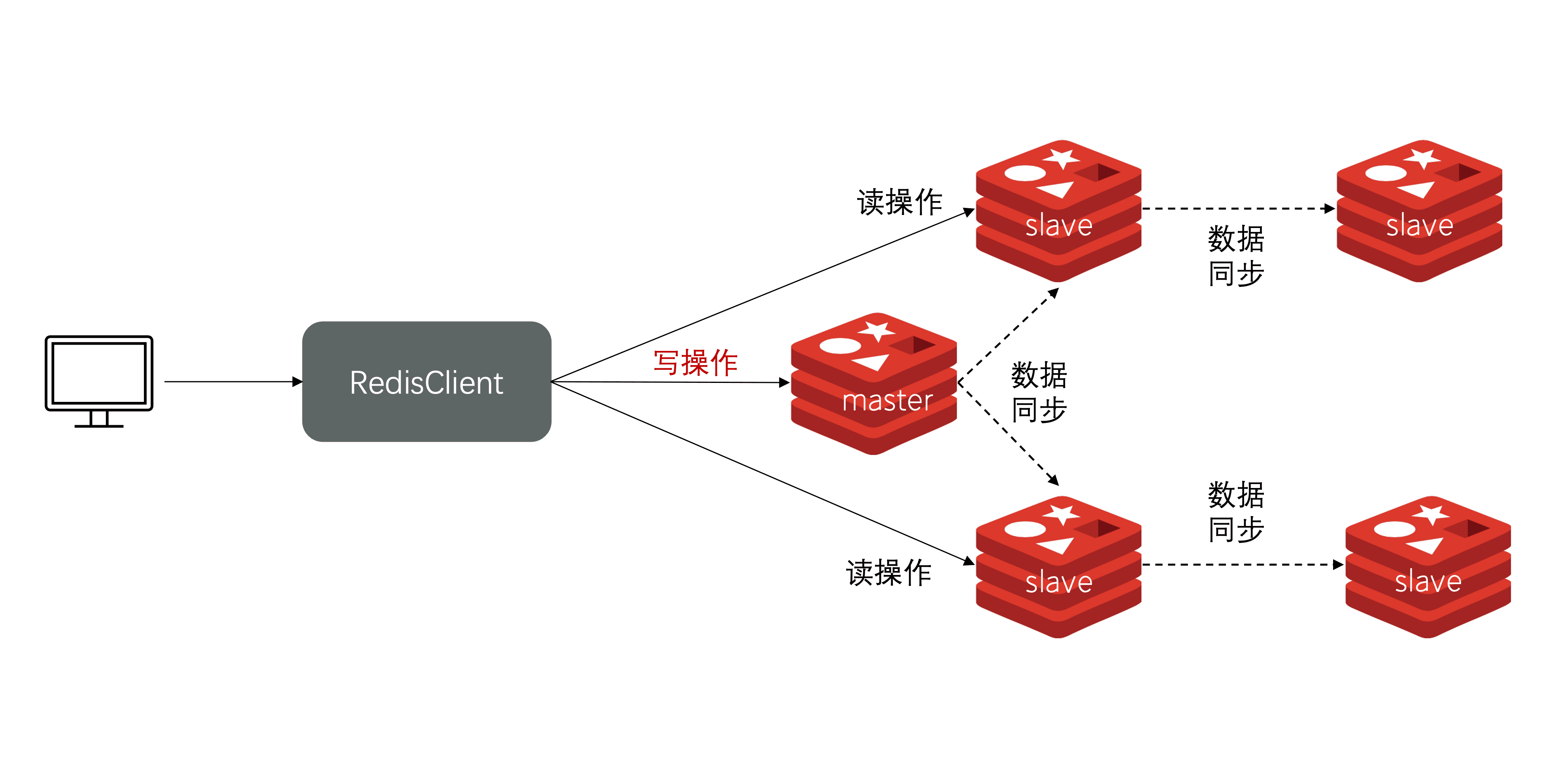
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
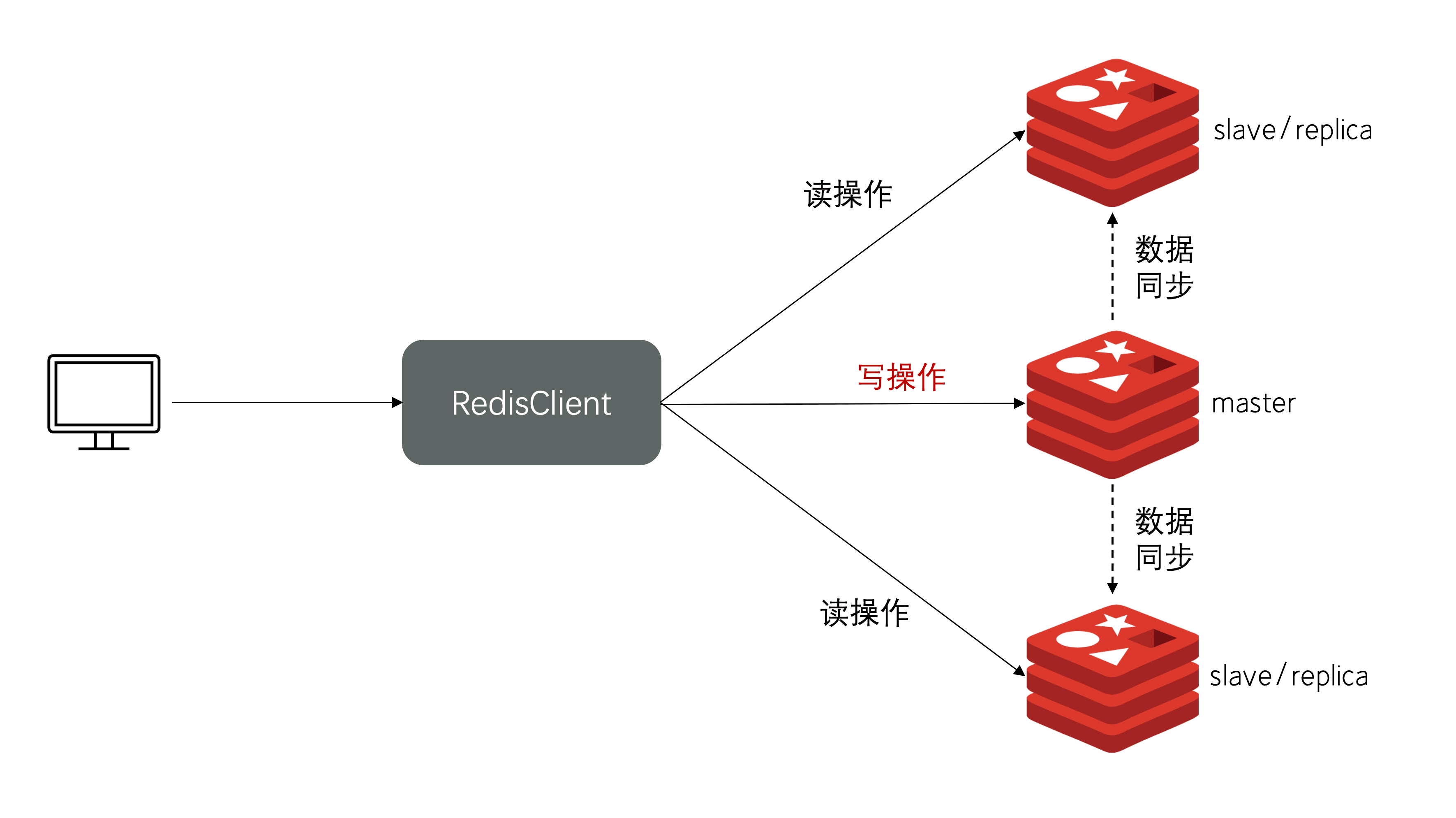
搭建主从集群
详情查看:
数据同步原理
全量同步
主从第一次同步是全量同步:
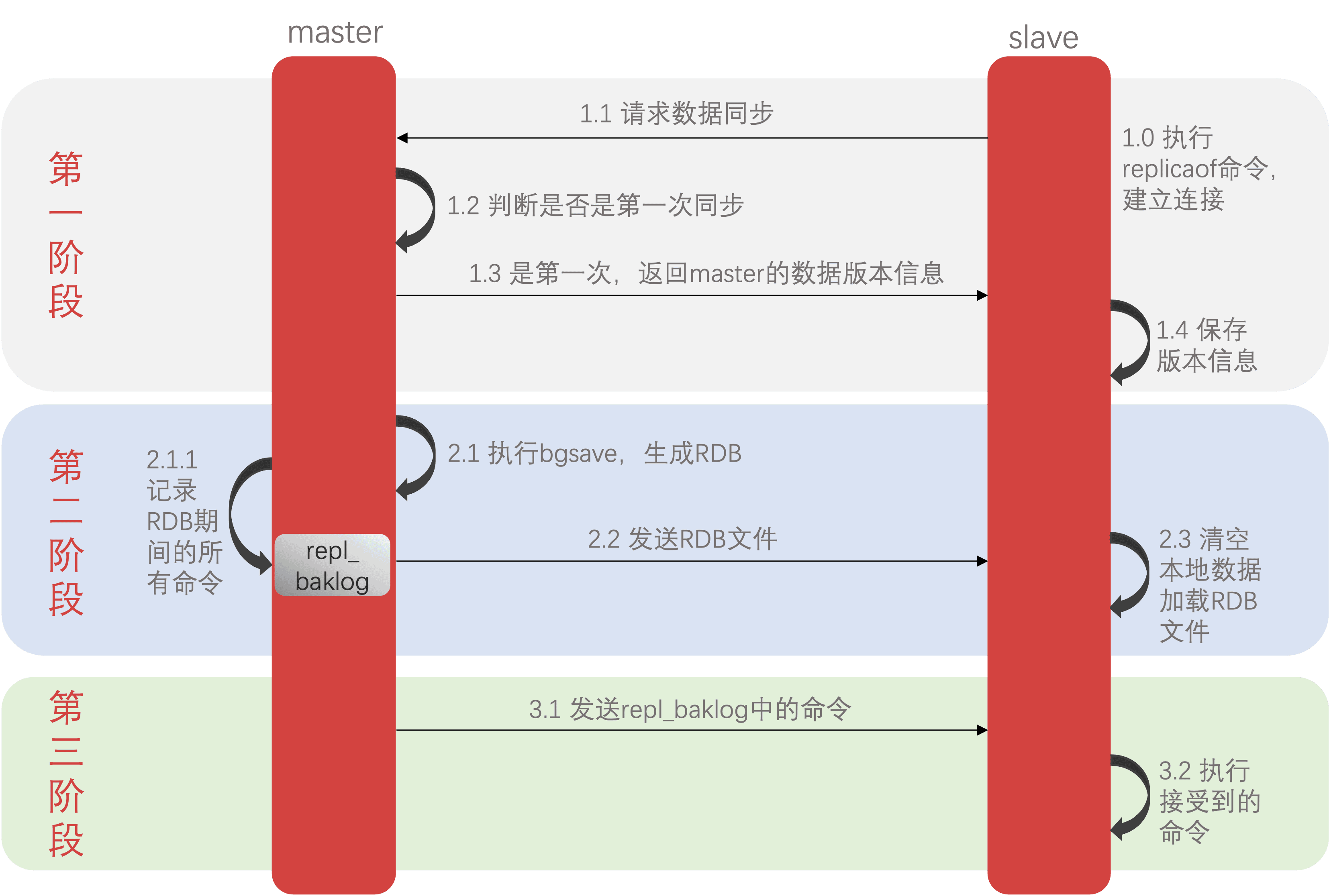
master如何判断slave是不是第一次来同步数据?这里会用到两个很重要的概念:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有一个唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id和offset,master才可以判断到底需要同步哪些数据。

详情可以查看打印的日志。
总结
简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在real_baklog,并持续将log中的命令发送给slave
- slave执行接受到的命令,保持与master之间的同步
增量同步
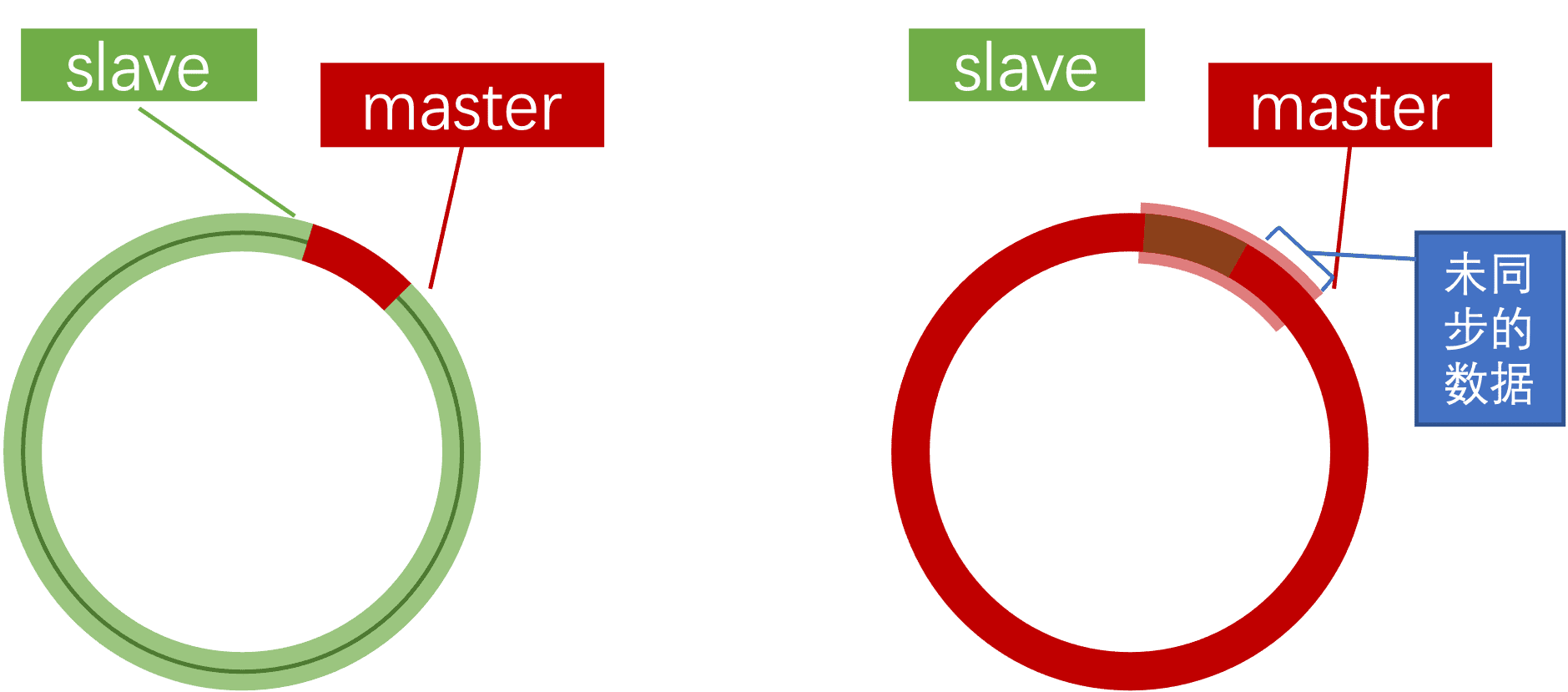
如果slave重启后同步,则执行增量同步

repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做数据增量同步,只能再次全量同步
优化
可以从以下几个方面来优化Redis主从集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点的内存占用不要太大,减少RDB导致过多的磁盘IO。
- 适当提高repl_baklog的大小,发现slave宕机时尽快故障恢复,尽可能避免全量同步。
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
总结
简述全量同步和增量同步的区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交给自己的offset到master,master获取real_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
Redis哨兵
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?
哨兵的作用和原理
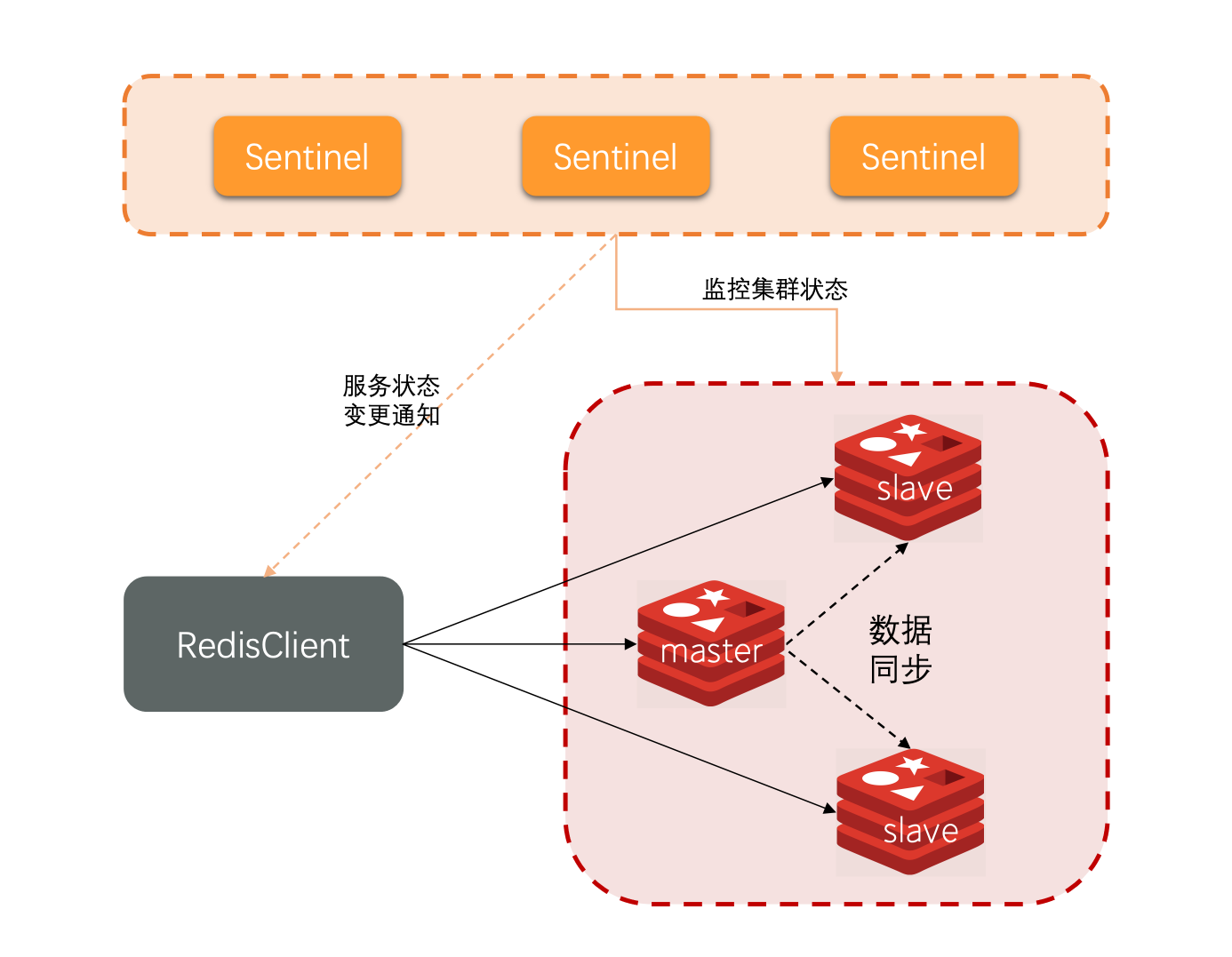
哨兵的作用
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
监控:Sentinel会不断检查您的master和slave是否按预期工作
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主。
通知:Sentinel充当Redis客户端的服务来源,当集群发生故障转移时,会讲最新信息推送给Redis的客户端
服务状态监控
Sentinel基于心跳机制检测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果sentinel节点发现某实例未在规定时间响应,则认为实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
选举新的master
一旦发现master故障,sentinel需要在slave中选择一个作为新的master,依据是这样的:
- 首先会判断salve节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
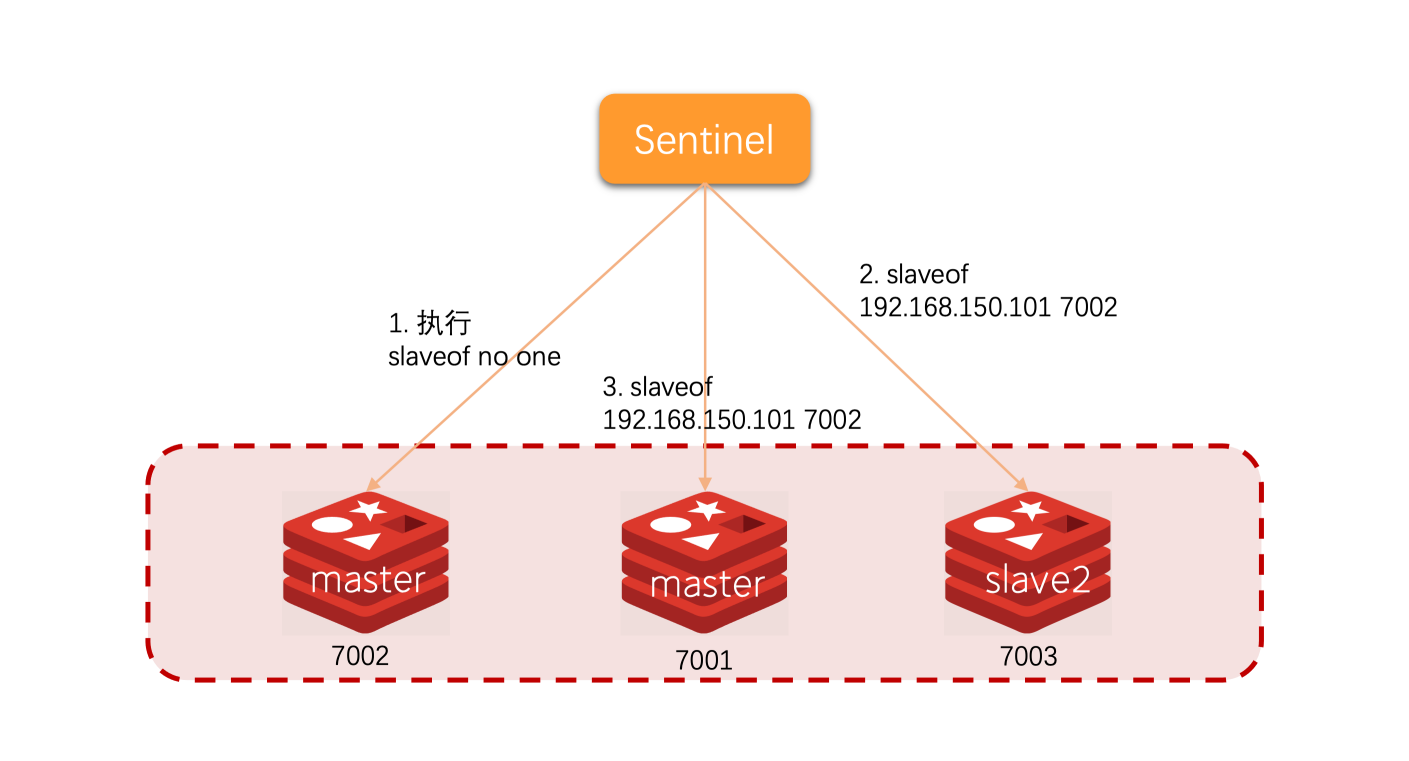
如何实现故障转移
当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下:
- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其他slave发送slaveof 192.168.150.101 7002命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点。
总结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如和判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
搭建哨兵集群
搭建过程可查看:
RedisTemplate的哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
搭建项目
新建一个Spring Boot项目,在pom中引入redis的starter依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>然后在配置文件
application.yml中指定sentinel相关信息:logging:
level:
io.lettuce.core: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.52.101:27001
- 192.168.52.101:27002
- 192.168.52.101:27003配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}这里的ReadFrom是配置Redis的读写策略,是一个枚举,包括下面选择:
MASTER:从主节点读取MASTER_PREFERRED:优先从master节点读取,master不可用才读取replicaREPLICA:从slave(replica)节点读取REPLICA_PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
写一个Controller
@RestController
public class HelloController {
private final StringRedisTemplate stringRedisTemplate;
public HelloController(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@GetMapping("/get/{key}")
public String hi(@PathVariable("key") String key) {
return stringRedisTemplate.opsForValue().get(key);
}
@GetMapping("/set/{key}/{value}")
public String hi(@PathVariable("key") String key, @PathVariable("value") String value) {
stringRedisTemplate.opsForValue().set(key, value);
return "success";
}
}
测试
访问http://localhost:8080/get/num,可以在日志中看到读命令是交给了slave7003
|
访问http://localhost:8080/set/num/666,可以在日志中看到写命令是交给了master7002
|
此时我们将主节点7002关掉,等待一段时间后,会看到7001成功成为新的master,来到IDEA项目的日志窗口,会看到打印了很多日志
|
可以看到到7001的flag=master
再次访问http://localhost:8080/get/num,可以看到是slave7003处理了GET命令。
|
Redis分片集群
分片集群结构
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题还没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可解决上述问题,分片集群特征:
- 集群中有多个master,每个master保持不同数据
- 每个master都可以有多个slave节点
- master之间通过ping检测彼此健康状态
- 客户端请求可以访问集群人意节点,最终都会被转发到正确节点
需要说明的是,分片集群里面的主从是不需要依赖哨兵的,当其中一个主节点宕机也是可以由另外的从节点顶替上
搭建分片集群
搭建过程可查看:
散列插槽
Redis会把每个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
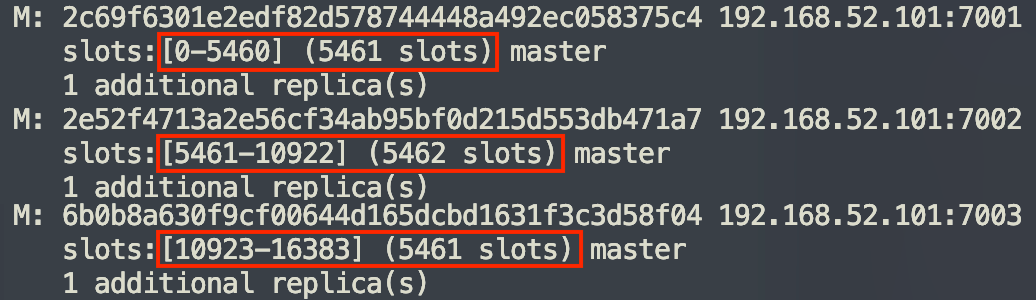
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含”{}”,且”{}”中至少包含1个字符,”{}”中的部分时有效部分
- key中不包含”{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方法是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
测试
使用下面命令连接Redis集群
|
set一个值
|
再set一个值
|
a计算得到的hash值为15495,该值所在的节点为7003
get一个值
|
再get一个值
|
可以看到已经切换到7001了
总结
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在的实例即可
如何将同一类数据固定的保持在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
集群伸缩
添加一个节点到集群
redis-cli –cluster提供了很多操作集群的命令,可以通过下面方式查看:
|
比如,添加节点和删除节点命令
|
添加一个新的master节点,并向其中存储num=10,其步骤如下:
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
具体操作
创建并启动实例
|
查看是否成功启动
|
添加到集群
|
查看是否添加成功
|
分配插槽,从7001到7004
|
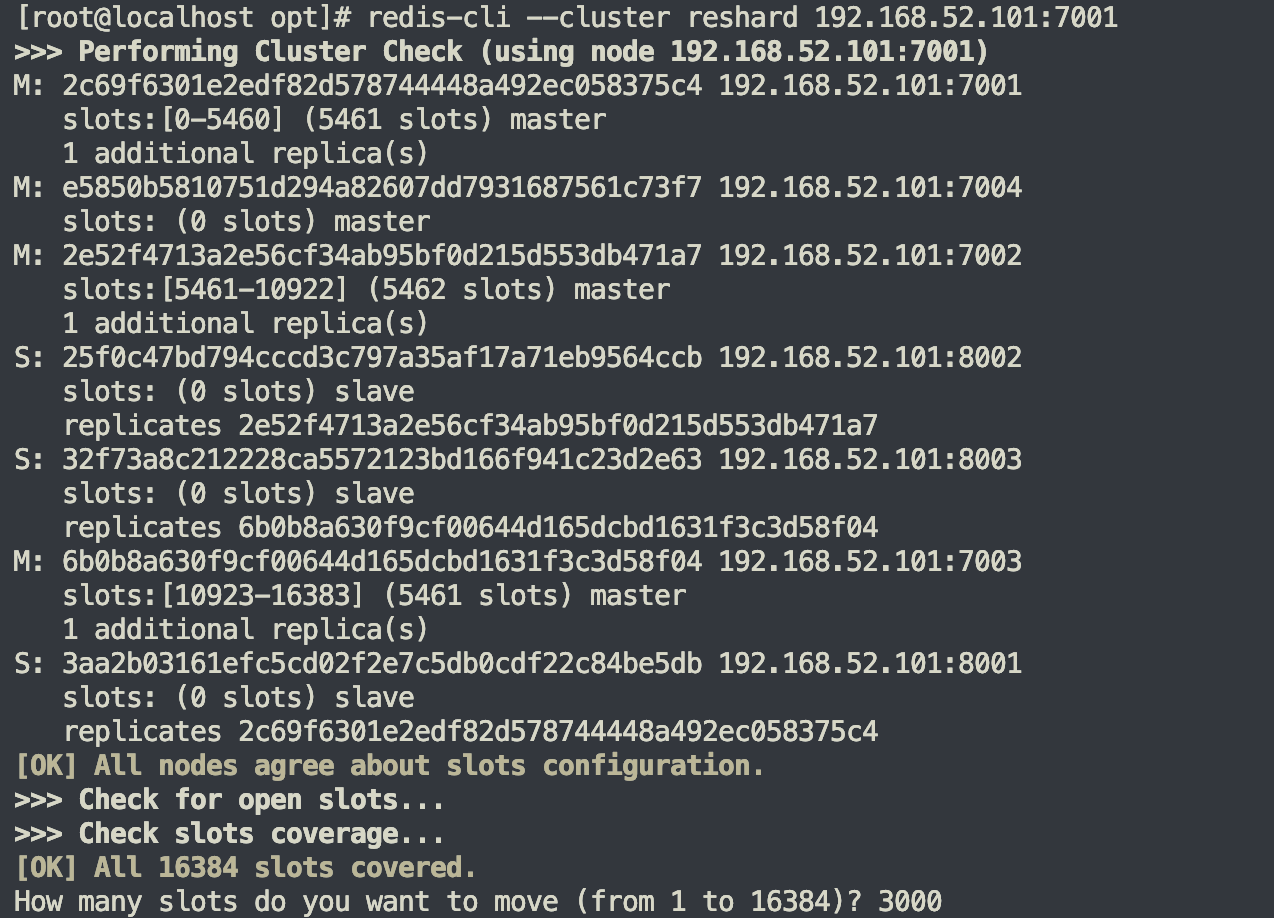
接下来的步骤会提示下面信息,根据自己需要填写即可
How many slots do you want to move (from 1 to 16384)?
- 这里我们直接输入3000,因为num的hash值是2765
What is the receiving node ID?
- 我们是要移动到7004,所以输入7004的ID,可以从上面复制
Please enter all the source node IDs.
Type ‘all’ to use all the nodes as source nodes for the hash slots. Type ‘done’ once you entered all the source nodes IDs.
- 插槽的数据源,我们是7001,所以填入7001的ID,同样从上面复制
- 输入
done继续
Do you want to proceed with the proposed reshard plan (yes/no)?
- 输入yes
查看是否分配成功
|
get一下num值
|
设置num的值为10
|
从集群删除一个节点
删除slave节点
|
删除master节点
先对节点进行分片工作,防止数据丢失
redis-cli --cluster reshard 欲删除节点ip:port移除节点
redis-cli --cluster del-node 节点ip:port 节点id
使用下面命令删除7004节点
|
- 分配步骤参考添加节点,目标是移动7004上的3000个插槽到7001
验证是否成功
|

故障转移
当集群中有一个master宕机会发生什么呢?
我们使用watch命令监听集群
|
再开启一个窗口,停止7002
|
等待一会我们看到7002 fail,而8002成为了master

我们再次启动7002
|
启动瞬间,7002成功连接集群,成为slave,实现了主从故障切换

数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
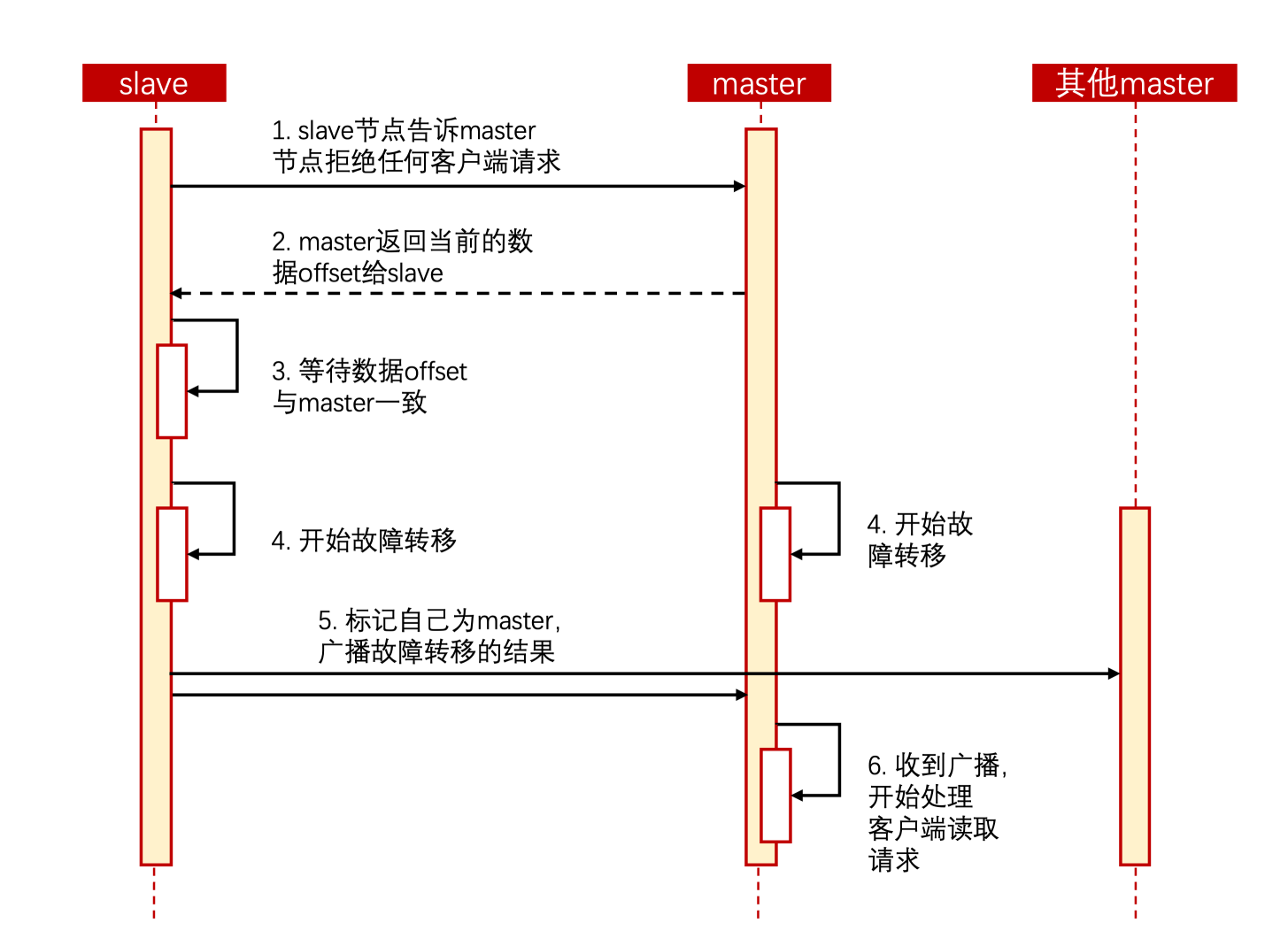
手动的Failover支持三种不同模式:
- 缺省:默认的流程,如图1~6步
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其他master的意见
在7002这个slave节点执行手动故障转移,重新夺回master地位
步骤如下:
利用redis-cli连接7002这个节点
redis-cli -c -p 7002执行cluster failover命令
CLUSTER FAILOVER
切换后通过命令查看状态
|
RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
搭建项目
新建一个Spring Boot项目,在pom中引入redis的starter依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>然后在配置文件
application.yml中指定sentinel相关信息:logging:
level:
io.lettuce.core: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
spring:
redis:
cluster:
nodes:
- 192.168.52.101:7001
- 192.168.52.101:7002
- 192.168.52.101:7003
- 192.168.52.101:8001
- 192.168.52.101:8002
- 192.168.52.101:8003配置主从读写分离,可省略
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer() {
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}这里的ReadFrom是配置Redis的读写策略,是一个枚举,包括下面选择:
MASTER:从主节点读取MASTER_PREFERRED:优先从master节点读取,master不可用才读取replicaREPLICA:从slave(replica)节点读取REPLICA_PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
写一个Controller
@RestController
public class HelloController {
private final StringRedisTemplate stringRedisTemplate;
public HelloController(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@GetMapping("/get/{key}")
public String hi(@PathVariable("key") String key) {
return stringRedisTemplate.opsForValue().get(key);
}
@GetMapping("/set/{key}/{value}")
public String hi(@PathVariable("key") String key, @PathVariable("value") String value) {
stringRedisTemplate.opsForValue().set(key, value);
return "success";
}
}
测试
访问http://localhost:8080/get/num
num是在7001中存储,日志中可以看出最后是交给了7001的从节点8001来执行,成功。
|
访问http://localhost:8080/set/num/666
set操作交给了7001,成功。
|
访问http://localhost:8080/set/a/666
set a 666的命令是切换到了7003来执行,成功。
|