截止2023年8月10号,使用百度云的内容审核只需要身份认证即可,且可领取免费的测试资源。
应用场景
- 用户评论过滤:对网站用户的评论信息进行检测,审核出涉及色情、暴恐、恶意推广等内容,保证良好的用户体验
- 注册信息筛查:对用户的注册信息进行筛查,避免黑产通过用户名实现违规信息的推广
- 文章内容审核:对UGC文章内容进行多个维度的审核,避免因内容违规导致的APP下架等损失
领取资源
百度云的内容审核各服务均提供一定额度的免费测试资源供测试使用,免费测试资源使用完毕后,可选择付费使用。
各接口免费测试资源可见免费测试资源文档介绍。
进入领取页面,根据情况选择领取接口,左下角0元领取
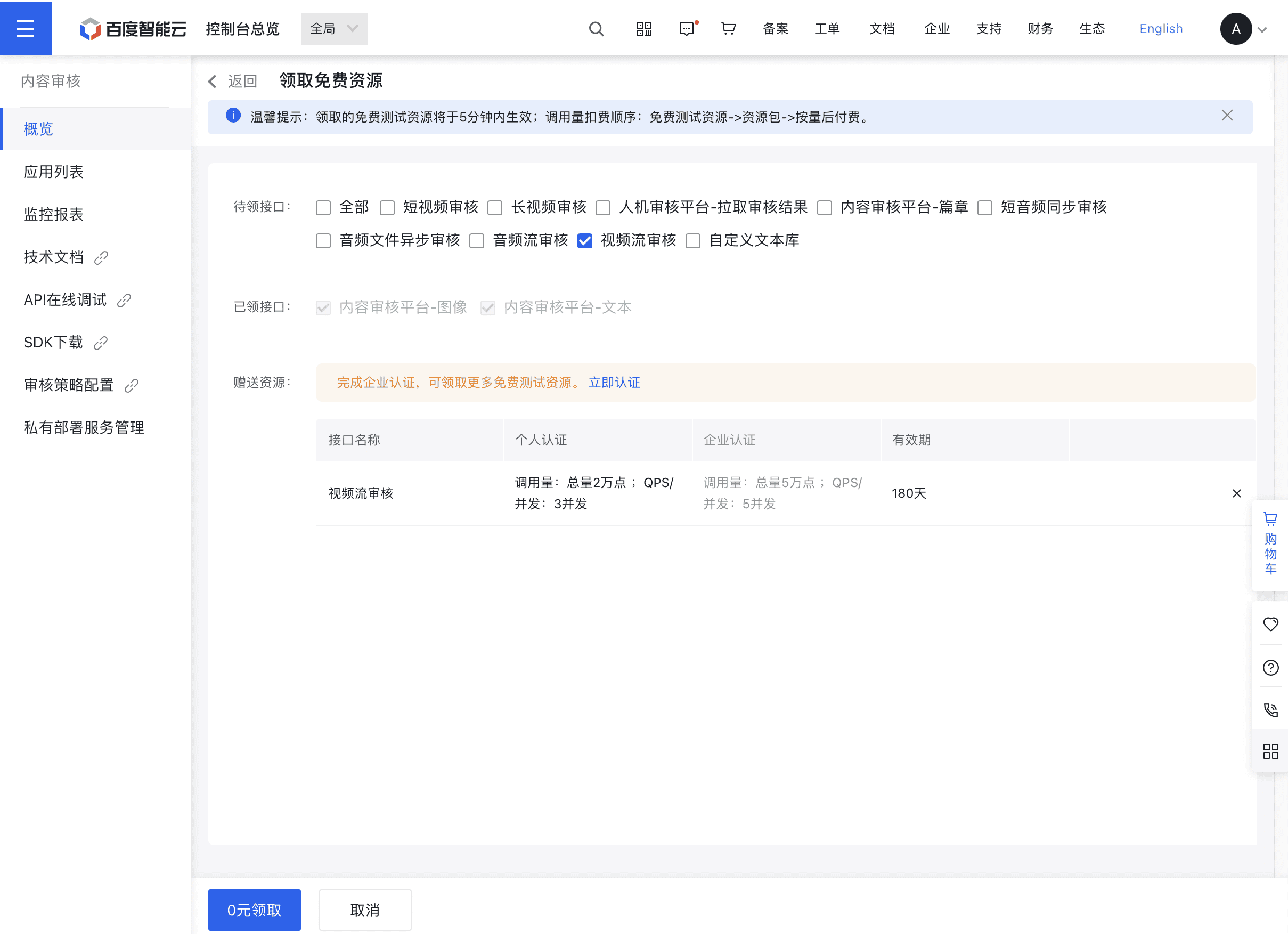
个人认证:
内容审核平台-文本:一次性赠送50,000次,2 QPS,有效期 365天;
内容审核平台-图像:一次性赠送10,000次,2 QPS,有效期 365天。
创建应用列表
调用百度AI服务需要Access_token,获取Access_token则需要通过应用的 API Key和 Secret Key,我们需要创建一个应用
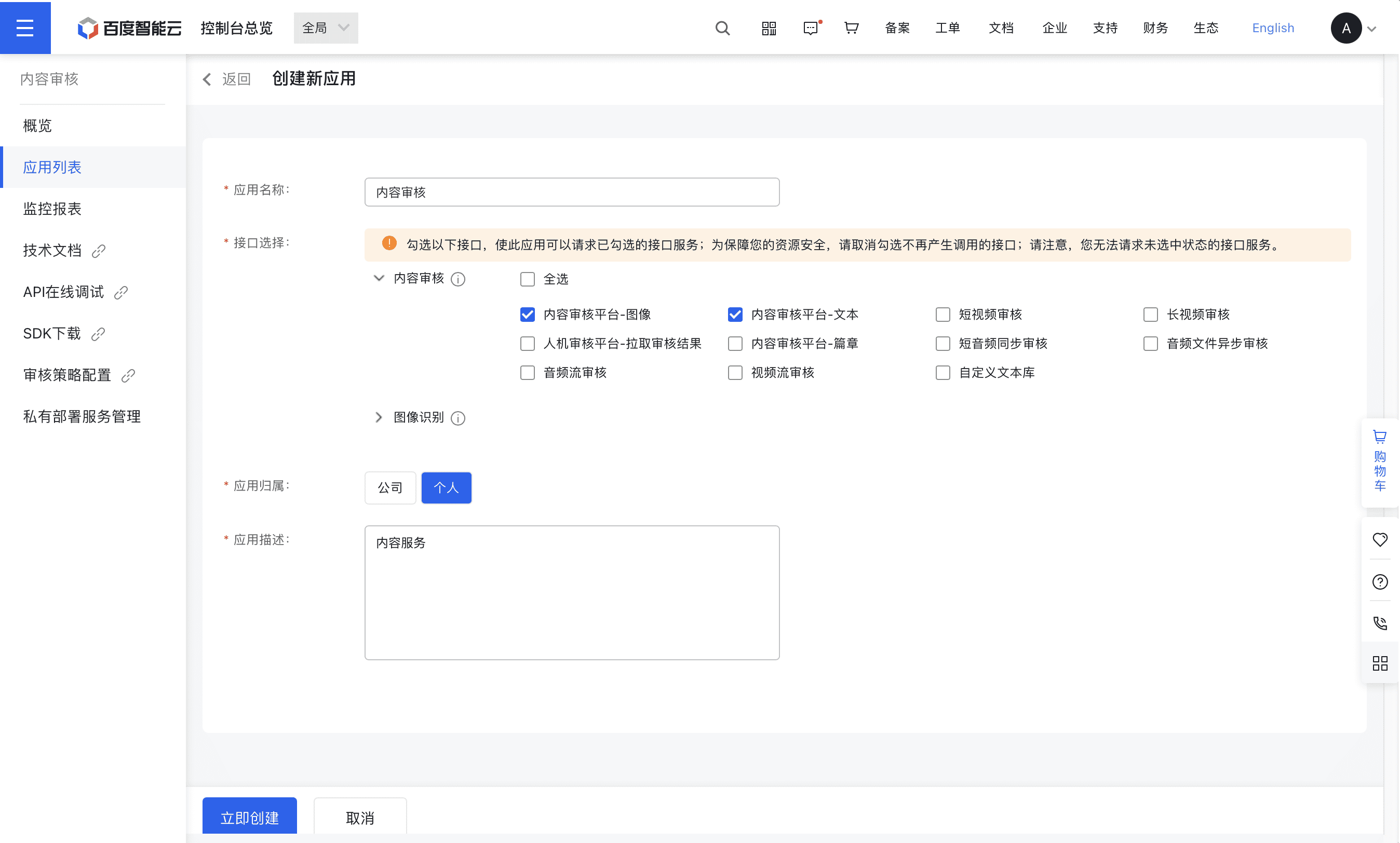
创建完成之后,我们就得到了 API Key 和 Secret Key
获取AccessToken
鉴权认证的主要目的是获取Access_token。Access_token是用户的访问令牌,承载了用户的身份、权限等信息。
使用我提供的工具类获取:
依赖:
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
|
内容审核服务
内容审核平台-文本
接口地址:https://aip.baidubce.com/rest/2.0/solution/v1/text_censor/v2/user_defined
请求方式:POST
接口名称:内容审核平台-文本
内容审核平台-图像
接口地址:https://aip.baidubce.com/rest/2.0/solution/v1/img_censor/v2/user_defined
请求方式:POST
接口名称:内容审核平台-图像
返回参数说明:
| 参数名称 | 数据类型 | 是否必须 | 备注 |
|---|---|---|---|
| log_id | Long | Y | 请求唯一id |
| error_code | Long | N | 错误提示码,失败才返回,成功不返回 |
| error_msg | String | N | 错误提示信息,失败才返回,成功不返回 |
| conclusion | String | N | 审核结果,可取值:合规、不合规、疑似、审核失败 |
| conclusionType | Integer | N | 审核结果类型,可取值1.合规,2.不合规,3.疑似,4.审核失败 |
成功响应案例
|
失败响应示例
|
代码实现
依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
|
常量的定义如下:
|
枚举类的定义如下:
|
自动装配
如果代码放在其他模块中,请使用该部分实现自动装配
在resources目录下创建META-INF/spring.factories,内容如下:
|
项目集成
以上内容可以放在工具模块或者公共模块中,在服务模块中食用方式如下:
引入依赖(非服务模块):
|
配置文件
|
- 填入上述步骤获取的 API Key(client-id) 和 Secret Key(client-secret)
使用文本审核
|
使用图像审核
关于接口需要数据有两种格式:
- Base64字符串,需要编码之后的(本文使用)
- 图片URL地址
|
Base64转换工具
|
自维护敏感词汇
可以使用DFA算法,使用确定有穷自动计机(一种数据结构)。